
The Process Is the Prompt
The limits of prompt engineering

Welcome to the 23rd edition of Black Box. This is the final part of Literature Review, where I dive into emerging research related to generative AI. Read the earlier parts here and here.

In “The Goldilocks Problem”, I framed generative AI as Deep Thought, the supercomputer from The Hitchhiker’s Guide to the Galaxy. As in the book, I believed the problem with LLMs was not their inability to answer but their inability to be asked. Constructing an effective prompt “requires a level of sophistication that its intended users do not have,” I observed. “Conversely, sophisticated users have no need for it.”
Looking back, I overstated the latter half of this thesis. Adams chose 42 as Deep Thought’s answer because it fit the caricature of his book. LLMs are obviously capable of more complex and meaningful tasks. But something about the first part still made sense to me, and I was curious if the science supported that intuition.
After reading a few dozen papers, I think that it does. In fact, I understated the former half. Prompt engineering is not about the specific words at all; it is about the thought process (or meta-process) contained in those words, explicitly or implicitly. Like how the medium is the message, the process is the prompt.
Show your work
First, some background. Prompt engineering is different from fine-tuning as no model weights are changed. The main prompt engineering paradigm is few-shot prompting, in which an LLM is given K demonstrations of a task at inference time as context. The demonstrations are usually cloze tests, or examples of masked texts (e.g., a question) with their desired completions. One-shot prompting is similar but with K = 1, and zero-shot only describes the task in natural language (without any examples).
(Though most of us know GPT-3 as a text generator, the paper’s importance in research is demonstrating few-shot prompting as an emergent property of LLMs, i.e., an ability not present in smaller models.)
Among the best known prompt engineering techniques is chain of thought (CoT), which applies the age-old elementary math advice of “showing your work” to LLMs. In CoT, an LLM is few-shot prompted with demonstrations that include intermediate “reasoning” steps. Wei et al. show that despite its simplicity, CoT significantly improves performance on word problems and reasoning tasks.
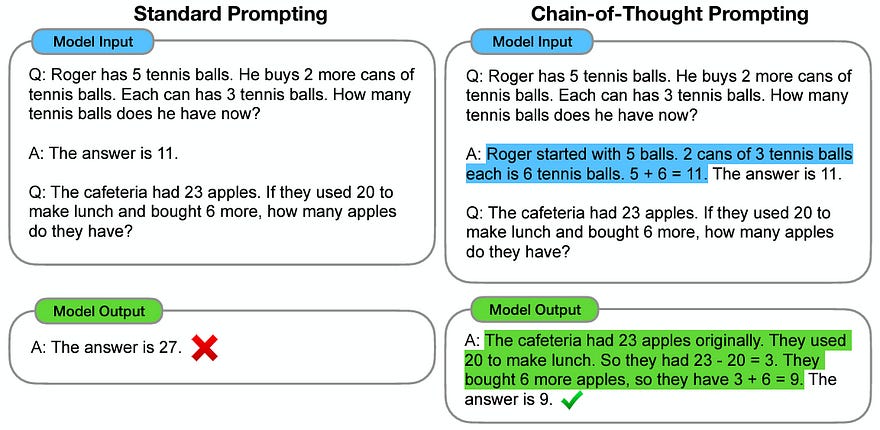
After trying it myself, I learned that CoT is not as simple as it seems. While I confirmed that the exact example doesn’t matter, CoT wouldn’t work with any old example containing intermediate steps. The example had to model a thought process that was logically similar to the real task. That was when I realized what mattered to the LLM was the process.
Process about process
But how do you get to that process? That is the big question. AI researcher Melanie Mitchell calls out this issue using language surprisingly similar to my description of the Goldilocks problem:
Two downsides of CoT prompting are 1) it takes some effort on the part of the human prompter to construct such prompts; and 2) often, being able to construct a CoT example to include in the prompt requires the prompter to already know how to solve the problem being given to the LLM!
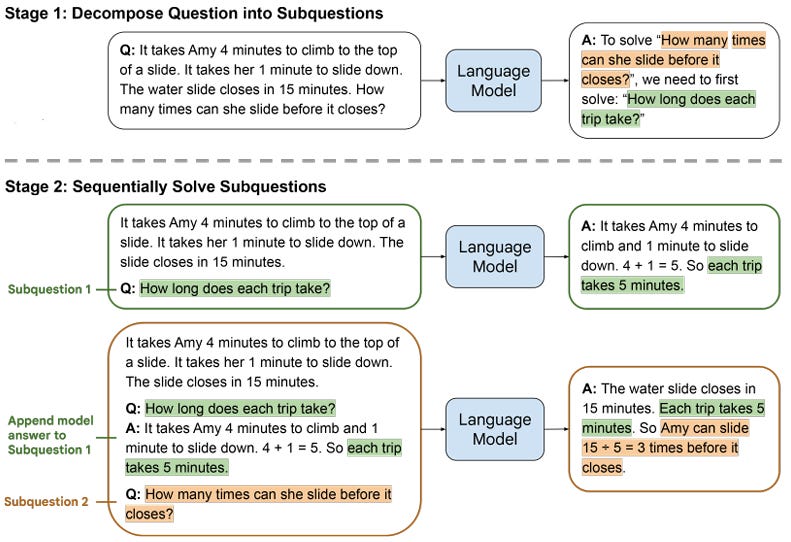
The easiest approach is having the LLM come up with the process, but that just kicking the can. What is the process to get to the process? And yet, this abstraction does somehow help. For example, least-to-most prompting has the LLM first decompose a problem into a sequence of sub-problems, then solve the problem by recursively applying sub-solutions. Recursion, in this case, is the meta-process.
Another example, which received some media coverage earlier this year, is asking the LLM to think step by step. Kojima et al. directly asked the model to propose a CoT reasoning path by giving it a task followed by the sentence “Let’s think step by step”. They concatenate this process to the first prompt plus the phrase “Therefore, the answer is” and feed it back into LLM.
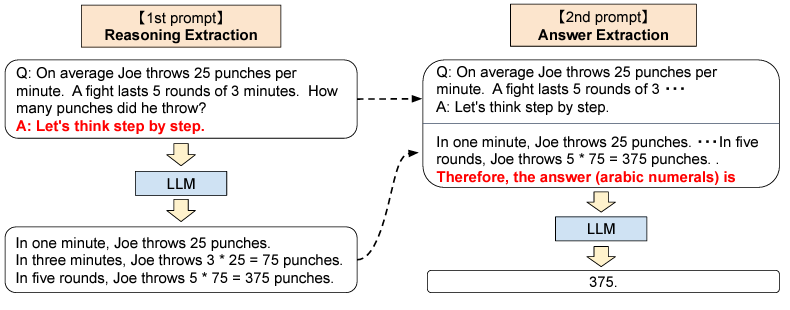
This is just the zero-shot version of CoT! In fact, my understanding is that any process can be generalized into a meta-process by translating it from few-shot to zero-shot. The meta-process can then be applied in a propose-evaluate prompt framework, as in these examples.
Playing Jeopardy
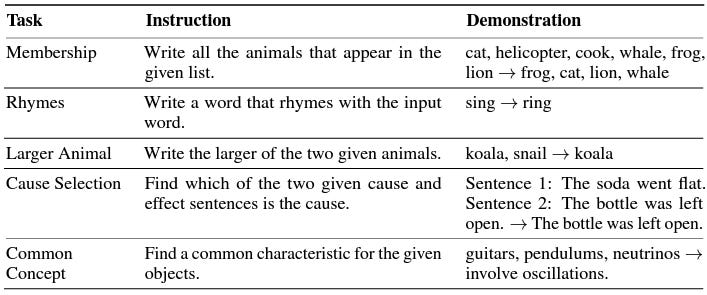
Meta-processes are an explicit way to get to processes, especially ones with intermediate steps (so-called multi-hop). There is also an implicit way: Give the LLM several input-output pairs and ask it to infer the process as a cloze test. This is effectively the inverse of few-shot prompting, which Honovich et al. point out in their paper:

While the setup is different, the problem is the same: Instruction induction still requires the prompter to already know the process in order to come up with consistent input-output pairs. Furthermore, Honovich et al. were able to show this ability only for single-hop processes like translation, although it is worth noting that some of these are abstract and non-obvious:
Despite its limitations, Zhou et al. demonstrate that this technique is useful for optimizing the prompt for a given process. They follow Honovich et al.’s method exactly, then have the LLM generate prompts that are semantically similar to the induced instruction. They evaluate these prompts by feeding each plus the inputs of the input-output pairs back to the LLM and scoring how close the generated outputs are to the original outputs. The optimized prompts for the test processes above, for example, are

But to claim that LLMs are “human-level prompt engineers”, which Zhou et al. do in the title of their paper, is an exaggeration. The prompt is a process, and I have yet to see research showing how an LLM could come up with the process on its their own. And so prompt engineering will always depend on the prompter knowing beforehand, and the prompted can only ever imitate what it receives. ∎
What are your favorite prompt engineering techniques? I’d love to hear about it @jwang_18 or reach out on LinkedIn.